

Normal formelfördelning, egenskaper, exempel, träning
- 1777
- 8
- Prof. Erik Johansson
De normal distribution o Gaussisk distribution är sannolikhetsfördelningen i kontinuerlig variabel, där sannolikhetsdensitetsfunktionen beskrivs av en exponentiell funktion av kvadratiskt och negativt argument, vilket resulterar i en flisad form.
Normalfördelningsnamnet kommer från det faktum att denna distribution är den som tillämpas på det största antalet situationer där någon kontinuerlig slumpmässig variabel är involverad i en given grupp eller befolkning.
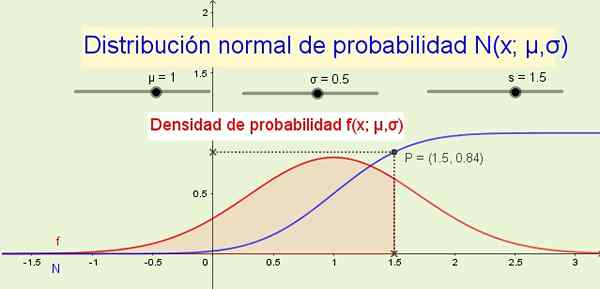
Figur 1. Normalfördelning N (x; μ, σ) och dess sannolikhetsdensitet F (S; μ, σ). (Egen utarbetande) Som exempel där normalfördelning tillämpas: höjden på män eller kvinnor, variationer i omfattningen av en viss fysisk storlek eller i mätbara psykologiska eller sociologiska egenskaper som den intellektuella kvoten eller konsumtionsvanorna för en viss produkt.
Å andra sidan kallas det Gaussian Distribution eller Gauss Bell, eftersom det är detta tyska matematiska geni som krediteras hans upptäckt för den användning han gav för beskrivningen av det statistiska felet i astronomiska mätningar redan 1800.
Det hävdas emellertid att denna statistiska distribution tidigare publicerades av en annan stor matematiker av franska ursprung, liksom Abraham de Moivre, tillbaka 1733.
[TOC]
Formel
Till normalfördelningsfunktionen i den kontinuerliga variabeln x, Med parametrar μ och σ Det betecknas av:
N (x; μ, σ)
Och uttryckligen är det skrivet så här:
N (x; μ, σ) = ∫-∞x f (s; μ, σ) ds
var f (u; μ, σ) Det är sannolikhetstäthetsfunktionen:
f (s; μ, σ) = (1/(σ√ (2π)) exp ( - s2/(2σ2)
Konstanten som multiplicerar den exponentiella funktionen i sannolikhetsdensitetsfunktionen kallas normaliseringskonstant och har valts på ett sådant sätt att:
N (+∞, μ, σ) = 1
Det tidigare uttrycket säkerställer att sannolikheten för att den slumpmässiga variabeln x vara mellan -∞ och +∞ antingen 1, det är 100% sannolikhet.
Parametern μ Det är det aritmetiska medelvärdet för den kontinuerliga slumpmässiga variabeln X och σ Standardavvikelsen eller kvadratroten för variansen för samma variabel. I det fall μ = 0 och σ = 1 Du har den normala standarden eller normalfördelningen typisk:
N (x; μ = 0, σ = 1)
Normalfördelningsegenskaper
1- Om en slumpmässig statistisk variabel följer en normal sannolikhetsdensitetsfördelning f (s; μ, σ), De flesta av uppgifterna grupperas runt genomsnittligt värde μ Och de är spridda runt dem så att precis över uppgifterna är mellan μ - σ och μ + σ.
Kan tjäna dig: absolut frekvens: formel, beräkning, distribution, exempel2- Standardavvikelsen σ Det är alltid positivt.
3- Formen för densitetsfunktionen F Det liknar en klocka, så den här funktionen kallas ofta Gaussian Bell eller Gaussian Function.
4- I en Gaussisk distribution sammanfaller median och mode och mode sammanfaller.
5- Böjningspunkterna för sannolikhetsdensitetsfunktionen finns exakt i μ - σ och μ + σ.
6- F-funktionen är symmetrisk med avseende på en axel som passerar med dess genomsnittliga värde μ Och du har noll asymptotiskt för x ⟶ +∞ och x ⟶ -∞.
7- Ett högre värde på σ Större spridning, brus eller distansering av data kring medelvärdet. Det vill säga till större σ Klockformen är mer öppen. Istället σ Small indikerar att tärningarna simmade till genomsnittet och klockans form är mer stängd eller spetsig.
8- Distributionsfunktionen N (x; μ, σ) indikerar sannolikheten för att den slumpmässiga variabeln är mindre än eller lika med x. Till exempel i figur 1 (ovan) sannolikheten P att variabeln x är mindre än eller lika med 1.5 är 84% och motsvarar området under funktionsdensitetsfunktionen f (x; μ, σ) Från -∞ till x.
Förtroendeintervall
9- Om uppgifterna följer en normalfördelning är 68,26% av dessa mellan μ - σ och μ + σ.
10- 95,44% av de uppgifter som följer en normalfördelning är mellan μ - 2σ och μ + 2σ.
11- 99,74% av de uppgifter som följer en normalfördelning är mellan μ - 3σ och μ + 3σ.
12- Om en slumpmässig variabel x Följ en distribution N (x; μ, σ), Sedan variabeln
Z = (x - μ) / σ Följ standardnormalfördelningen N (z; 0,1).
Förändringen av variabeln x till z Det kallas standardisering eller typifikation och är mycket användbar vid tillämpningen av standardfördelningstabellerna på data som följer en normal icke-standardfördelning.
Normalfördelningsapplikationer
För att tillämpa normalfördelningen är det nödvändigt att gå igenom beräkningen av integralen av sannolikhetstätheten, som ur analytisk synvinkel inte är lätt och inte alltid är tillgängligt ett datorprogram som tillåter dess numeriska beräkning. För detta ändamål används standard- eller typificerade värdentabeller, vilket är inget annat än normalfördelningen i fallet μ = 0 och σ = 1.
Kan tjäna dig: kombinerade operationer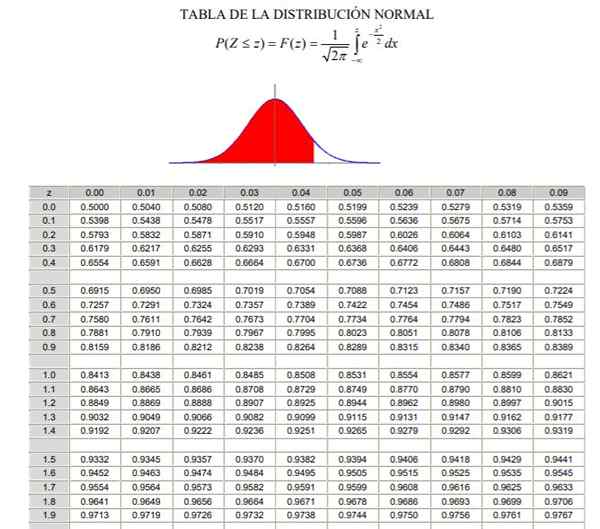 Normalfördelningstabell typiserad (del 1/2)
Normalfördelningstabell typiserad (del 1/2) 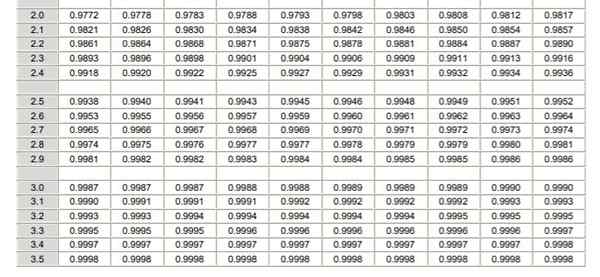 Normalfördelningstabell typiserad (del 2/2)
Normalfördelningstabell typiserad (del 2/2) Det bör noteras att dessa tabeller inte innehåller negativa värden. Men med hjälp av symmetriegenskaperna för den gaussiska sannolikhetsdensitetsfunktionen kan motsvarande värden erhållas. I den upplösta övningen som visas nedan anges användningen av tabellen i dessa fall.
Exempel
Antag att du har en slumpmässig datauppsättning X som följer en normal genomsnittlig fördelning på 10 och standardavvikelse 2. Det uppmanas att hitta sannolikheten att:
a) Den slumpmässiga variabeln x är mindre än eller lika med 8.
b) är mindre än eller lika med 10.
c) Den variabeln X är under 12.
d) sannolikheten för att ett x -värde är mellan 8 och 12.
Lösning:
a) För att svara på den första frågan måste du bara beräkna:
N (x; μ, σ)
Med x = 8, μ = 10 och σ = 2. Vi inser att det är en integral som inte har en analytisk lösning i elementära funktioner, men lösningen uttrycks enligt felfunktionen ERF (x).
Å andra sidan finns det möjligheten att lösa integralen på ett numeriskt sätt, vilket är vad många kalkylatorer, kalkylblad och datorprogram som Geogebra gör. Följande figur visar den numeriska lösningen som motsvarar det första fallet:
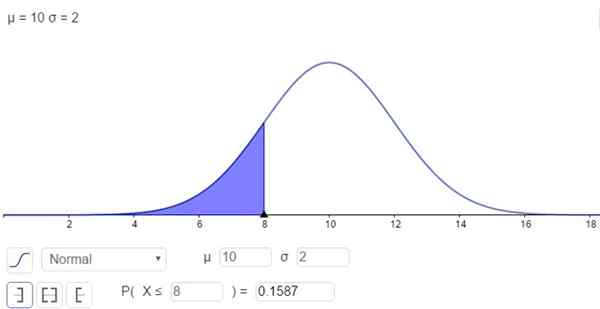 figur 2. Sannolikhetstäthet F (x; μ, σ). Det skuggade området representerar P (x ≤ 8). (Egen utarbetande)
figur 2. Sannolikhetstäthet F (x; μ, σ). Det skuggade området representerar P (x ≤ 8). (Egen utarbetande) Och svaret är att sannolikheten för att X är under 8 är:
P (x ≤ 8) = n (x = 8; μ = 10, σ = 2) = 0,1587
b) I det här fallet handlar det om att hitta sannolikheten för att den slumpmässiga variabeln x är under genomsnittet att i detta fall är värt 10. Svaret kräver ingen beräkning, eftersom vi vet att hälften av uppgifterna är under genomsnittet och den andra hälften över genomsnittet. Därför är svaret:
P (x ≤ 10) = n (x = 10; μ = 10, σ = 2) = 0,5
c) För att svara på den här frågan måste du beräkna N (x = 12; μ = 10, σ = 2), vilket kan göras med en räknare som har statistiska funktioner eller av programvara som Geogebra:
Kan tjäna dig: delare av 8: vad är och enkel förklaring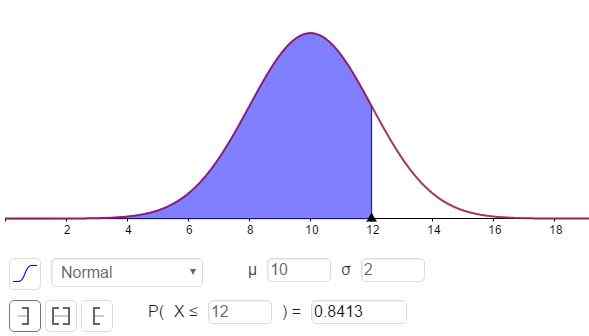 Figur 3. Sannolikhetstäthet F (x; μ, σ). Det skuggade området representerar P (x ≤ 12). (Egen utarbetande)
Figur 3. Sannolikhetstäthet F (x; μ, σ). Det skuggade området representerar P (x ≤ 12). (Egen utarbetande) Svaret på del C kan ses i figur 3 och är:
P (x ≤ 12) = n (x = 12; μ = 10, σ = 2) = 0,8413.
d) För att hitta sannolikheten för att den slumpmässiga variabeln X är mellan 8 och 12 kan vi använda resultaten från delarna A och C enligt följande:
P (8 ≤ x ≤ 12) = P (x ≤ 12) - P (x ≤ 8) = 0,8413 - 0,1587 = 0,6826 = 68,26.
Träning löst
Det genomsnittliga priset för ett företags aktier är $ 25 med en standardavvikelse på $ 4. Bestäm sannolikheten för att:
a) En åtgärd har en kostnad mindre än $ 20.
b) som har en kostnad större än $ 30.
c) Priset är mellan $ 20 och $ 30.
Använd de normala distributionstabellerna som kännetecknas för att hitta svaren.
Lösning:
För att använda tabellerna är det nödvändigt att flytta till den normaliserade eller typfulla variabeln:
$ 20 i den standardiserade variabla lika lika med Z = ($ 20 - $ 25) / $ 4 = -5/4 = -1,25 och
$ 30 i den standardiserade variabla lika lika med Z = ($ 30 - $ 25) / $ 4 = +5/4 = +1,25.
A) $ 20 motsvarar -1,25 i den standardiserade variabeln, men tabellen har inga negativa värden, så vi placerar +1,25 -värdet som visar värdet 0,8944.
Om detta värde subtraheras 0,5 kommer resultatet att vara området mellan 0 och 1,25 som förresten är identiskt (efter symmetri) till området mellan -1.25 och 0. Subtraktionsresultatet är 0,8944 - 0,5 = 0,3944 vilket är området mellan -1.25 och 0.
Men områdesintressen från -1 till -1,25 som kommer att vara 0,5 -0,3944 = 0,1056. Det dras därför slutsatsen att sannolikheten för att en åtgärd är under $ 20 är 10,56%.
b) $ 30 i den typifierade variabeln är 1,25. För detta värde i tabellen visas numret 0.8944 som motsvarar området från -∞ till +1.25. Området mellan +1.25 y +∞ är (1 - 0,8944) = 0,1056. Med andra ord, sannolikheten för att en åtgärd kostar mer än $ 30 är 10,56%.
c) sannolikheten för att en åtgärd har en kostnad mellan $ 20 och $ 30 kommer att beräknas enligt följande:
100% -10,56% - 10,56% = 78,88%
Referenser
- Statistik och sannolikhet. Normal distribution. Hämtad från: ProjectoDescartes.org
- Geogebra. Klassisk geogebra, beräkning av sannolikhet. Återhämtat sig från Geogebra.org
- Matematik. Gauss distribution. Återhämtad från: är.Matematik.com
- Mendenhall, W. 1981. Statistik för administration och ekonomi. 3: e. utgåva. Iberoamerica redaktion.
- Statlig vandring. Lär dig självstatistik. Poisson Distribution. Återhämtat sig från: StatTrek.com,
- Triola, m. 2012. Grundstatistik. 11th. Ed. Pearson Education.
- University of Vigo. Huvudsakliga kontinuerliga distributioner. Återhämtat sig från: Anapg.webbplatser.Uvigo.är
- Wikipedia. Normal distribution. Återhämtad från: är.Wikipedia.org
- « Xinca -kulturhistoria, plats, egenskaper, världsbild, tullar
- Haptes historia, funktioner, egenskaper, inmunes svar »