

Slumpmässig felformel och ekvationer, beräkning, exempel, övningar
- 2268
- 467
- Per Karlsson
han slumpmässigt fel av en fysisk mängd består av de icke -förutsägbara variationerna av måtten på det beloppet. Dessa variationer kan produceras av fenomenet som mäts av mätinstrumentet eller av observatören själv.
Sådant fel beror inte på att något har gjorts fel under experimentet, utan att det är ett fel som är inneboende i mätprocessen eller det studerade fenomenet. Detta orsakar måtten uppmätt ibland lite större och ibland lite lägre, men svänger vanligtvis runt ett centralt värde.
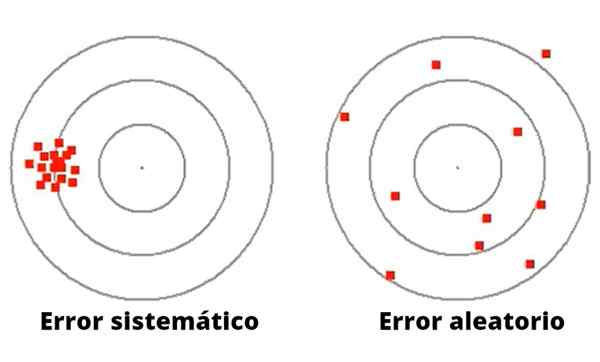
Figur 1- Slumpmässiga fel varierar i storlek och riktning. Tvärtom, systematiska fel tenderar att vara konsekvent. Till skillnad från slumpmässigt fel kan systematiskt fel orsakas av dålig kalibrering eller en olämplig skalfaktor i mätinstrumentet, inklusive ett fel i experimentutrustningen eller en olämplig observation, vilket orsakar en avvikelse i samma mening.
Figur 1 illustrerar skillnaden mellan systematiskt och slumpmässigt fel i Dart -lanseringsspelet till ett mål med cirklar.
När det gäller vänster är darten koncentrerade runt en mycket långt från mitten. Pitcher för dessa dartar, även om det är av gott mål, har ett systematiskt misslyckande, kanske av visuellt ursprung eller i vägen för att kasta.
Å andra sidan har kannan till höger (i figur 1) en stor spridning runt det centrala målet, därför är det en mycket oprestad kanna, med ett dåligt mål, som ofrivilligt gör slumpmässigt fel.
[TOC]
Formler och ekvationer i slumpmässigt fel
När mätprocessen visar slumpmässigt fel är det nödvändigt.
Naturligtvis är det i varje mätning nödvändig att se till att förhållandena där de utförs alltid är desamma.
Kan tjäna dig: Faraday Law: Formel, enheter, experiment, träning,Anta att mätningen upprepas n Times. Eftersom det finns slumpmässigt fel i varje mätning kommer det att finnas något annorlunda värde. Anta att uppsättningen n Mätningar är:
x1, x2, x3,..., xn
Så vilken värderapport för mått?
Genomsnittligt värde och standardavvikelse
De medelvärde antingen genomsnitt av uppsättningen av åtgärder, som vi betecknar och beräknas enligt följande:
= (x1 + x2 + x3 +... +xn) / n
Standardavvikelse
Detta resultat har emellertid en felmarginal som ges av standardavvikelsen. För att definiera det måste du först veta avvikelsen och sedan variansen:
-Avvikelsen dYo att varje uppmätt värde har Xi När det gäller medelvärdet är:
dYo = xYo -
Om genomsnittet av avvikelserna beräknades skulle det systematiskt erhållas = 0, givet att:
= (D1 + d2 + d3 +... +Dn) /n =
= [x1 - ) + (x2 - ) +... +(xn - )]/n
= (x1+ x2 +... + xn) / n - n / n = - = 0
-Genomsnittet av avvikelser är inte användbart för att veta spridningen av åtgärderna. Å andra sidan betecknar medelvärdet för kvadratet av avvikelser eller varians, av σ2, Ja det är det.
Det beräknas enligt följande formel:
σ2 = (D12 + d22 +.. .+ dn2 ) / (N -1)
I statistik kallas detta belopp variation.
Och vid kvadratroten av variansen är det känt som Standardavvikelse σ:
σ = √ [(D12 + d22 +.. .+ dn2 ) / (n -1)]
Standardavvikelsen σ indikerar att:
1.- 68% av de gjorda mätningarna ingår i intervallet [ - σ, + σ].
2.- 95% av mätningarna är i intervallet [ - 2σ, + 2σ].
3.- 99,7% av de åtgärder som vidtas ligger i sortimentet [ - 3σ, + 3σ].
Hur man beräknar slumpmässigt fel?
Mätresultatet är medelvärde av n Mätningar betecknade och beräknas enligt följande formel:
Kan tjäna dig: areolär hastighet: hur det beräknas och lösta övningar= (∑xYo) / n
Det är emellertid inte det "exakta" värdet på mätningen, eftersom det påverkas av slumpmässigt fel ε, som beräknas så här:
ε = σ / √n
Var:
σ = √ [(∑ (xi -)2 ) / (n -1)]
Det slutliga resultatet av mätningen måste rapporteras på något av följande sätt:
- ± σ / √n = ± ε Med en 68% konfidensnivå.
- ± 2σ / √n = ± 2ε Med 95% konfidensnivå.
- ± 3σ / √n = ± 3ε Med 99,7% konfidensnivå.
Det slumpmässiga felet påverkar den sista betydande figuren av mätningen, som vanligtvis sammanfaller med uppskattningen av mätinstrumentet. Men om det slumpmässiga felet är mycket stort kan de två sista betydande siffrorna påverkas av variation.
Exempel på slumpmässiga fel
Slumpmässiga fel kan visas i olika fall där en åtgärd görs:
Mäta en längd med ett måttband eller regel
När en längd mäts med en regel eller ett bandmått och avläsningarna faller mellan skalans varumärken, uppskattas det mellanvärdet.
Ibland har uppskattningen överskott och annan defekt, så slumpmässigt fel införs i mätprocessen.
 figur 2. Slumpmässiga fel kan visas när en längd mäts med en bandband. Källa: Pikrepo.
figur 2. Slumpmässiga fel kan visas när en längd mäts med en bandband. Källa: Pikrepo. Vindens hastighet
Vid mätningen av vindens hastighet kan det finnas förändringar i läsningen från ett ögonblick till en annan på grund av fenomenets förändrade natur.
När du läser volymen i en graderad cylinder
När volymen läses med en graderad cylinder, till och med försöker minimera parallagefelet, varje gång det mäts, förändras meniskobservationsvinkeln lite, varför åtgärderna påverkas av slumpmässigt fel.
Det kan tjäna dig: första jämviktstillstånd: Förklaring, exempel, övningar Figur 3.- I kemilaboratoriet är det möjligt att göra slumpmässiga misstag i att läsa en kandidatcylinder. Källa: Pexels.
Figur 3.- I kemilaboratoriet är det möjligt att göra slumpmässiga misstag i att läsa en kandidatcylinder. Källa: Pexels. När ett barns status mäts
Genom att mäta höjden på ett barn, särskilt om det är lite rastlös, gör det små hållningsförändringar något förändring av läsning.
När du använder badrumsskalan
När vi vill mäta vår vikt med ett badrum kan en liten förändring i stödpunkten till och med en positionsförändring slumpmässigt påverka mätningen.
Träning löst
En leksaksvagn får rulla längs ett rakt och lutande spår och mätt med ett stoppur den tid som tar hela spåret.
Mätningen görs 11 gånger, med vård av att släppa vagnen från samma plats, utan att ge någon impuls och hålla lutningen fixar.
Uppsättningen av erhållna resultat är:
3,12S 3.09S 3.04S 3.04S 3.10S 3.08S 3.05S 3.10S 3.11S 3.06S, 3.03S
Vad är det slumpmässiga felet i åtgärderna?
 Figur 4. Tar tid för en leksakstrolle som går ner genom ett lutande plan. Källa: Fanny Zapata.
Figur 4. Tar tid för en leksakstrolle som går ner genom ett lutande plan. Källa: Fanny Zapata. Lösning
Som man kan se är de erhållna resultaten inte unika och varierar något.
Den första är att beräkna det genomsnittliga härkomsttidsvärdet och erhålla 3.074545455 sekunder.
Det är inte meningsfullt att upprätthålla så många decimaler, eftersom varje mätning har tre betydande siffror och det andra decimalen av varje åtgärd är osäker, eftersom det är vid uppskattningen av stoppuret, därför avrundas resultatet till två decimaler:
= 3,08 s.
Med räknaren i statistiskt läge är standardavvikelsen σ = 0,03 s Och standardfelet är σ / √11 = 0,01 s. Det slutliga resultatet uttrycks enligt följande:
Övergångstid
3,08 s ± 0,01s (med 68%konfidensnivå)
3,08 s ± 0,02s (med 95%konfidensnivå)
3,08 s ± 0,03s (med 99,7%konfidensnivå)
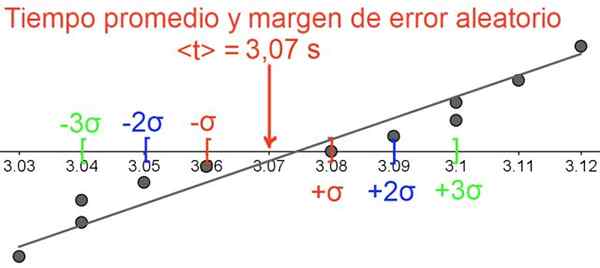 Figur 5. Den slumpmässiga felmarginalen, notera att uppgifterna är grupperade runt medelvärdet. Källa: f. Zapata.
Figur 5. Den slumpmässiga felmarginalen, notera att uppgifterna är grupperade runt medelvärdet. Källa: f. Zapata. Referenser
- Canavos, g. 1988. Sannolikhet och statistik: Tillämpningar och metoder. McGraw Hill.
- Devore, j. 2012. Sannolikhet och statistik för teknik och vetenskap. 8th. Utgåva. Häck.
- Helmestine A. Slumpmässigt fel vs. Systematisk. Återhämtat sig från: tankco.com
- Laredo, e. Mittfel. Återhämtat sig från: USB.gå.
- Levin, r. 1988. Statistik för administratörer. 2: a. Utgåva. Prentice hall.
- « Ekonomi för Aztecs eller Mexica -egenskaper och aktiviteter
- Omvända trigonometriska funktioner, härledda, exempel, övningar »