

Slumpmässig provtagningsmetodik, fördelar, nackdelar, exempel

- 2730
- 46
- Johan Eriksson
han slumpmässigt urval Det är sättet att välja ett statistiskt representativt prov från en given population. En del av principen att varje element i provet måste ha samma sannolikhet för att väljas.
En lotteri är ett exempel på slumpmässig provtagning, där varje medlem av deltagarna tilldelas ett nummer. För att välja siffrorna som motsvarar The Raffle Awards (provet) används en viss slumpmässig teknik, till exempel extrahera från en brevlåda siffrorna som fick på identiska kort.
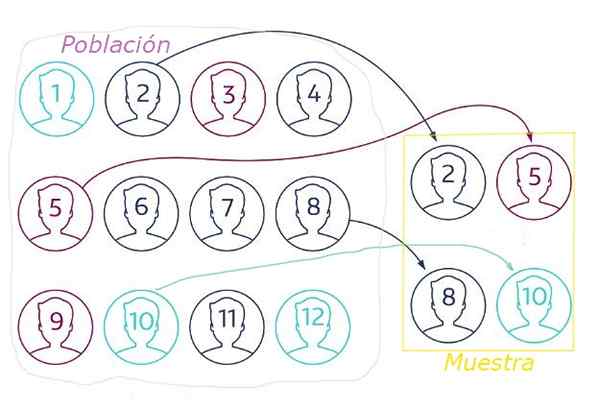 Figur 1. Vid slumpmässig provtagning extraheras provet från slumpmässig population genom någon teknik som säkerställer att alla element har samma sannolikhet för att väljas. Källa: NetQuest.com.
Figur 1. Vid slumpmässig provtagning extraheras provet från slumpmässig population genom någon teknik som säkerställer att alla element har samma sannolikhet för att väljas. Källa: NetQuest.com. Vid slumpmässig provtagning är det viktigt.
[TOC]
Storleken på provet
Det finns formler för att bestämma den korrekta storleken på ett prov. Den viktigaste faktorn att tänka på är om befolkningsstorleken är känd eller inte. Låt oss titta på formlerna för att bestämma provstorleken:
Fall 1: Befolkningsstorlek är inte känd
När befolkningens storlek är okänd är det möjligt att välja ett adekvat N -prov, för att avgöra om en viss hypotes är sann eller falsk.
För detta används följande formel:
n = (z2 P q)/(e2)
Var:
-P Det är sannolikheten att hypotesen är sant.
-Q är sannolikheten för att den inte är, därför q = 1 - p.
-E är den relativa felmarginalen, till exempel ett 5% -fel har en marginal E = 0,05.
-Z har att göra med den nivå av förtroende som krävs av studien.
Kan tjäna dig: Normal Distribution: Formel, Egenskaper, exempel, träningI en normalfördelning som typiseras (eller normaliserad) har en 90% konfidensnivå z = 1 645, eftersom sannolikheten för att resultatet är mellan -1 645σ och +1,645σ är 90%, där σ är standardavvikelsen.
Förtroendenivåer och deras motsvarande Z -värden
1.- 50% konfidensnivå motsvarar z = 0,675.
2.- 68.3% konfidensnivå motsvarar z = 1.
3.- 90% konfidensnivå motsvarande z = 1 645.
4.- 95% konfidensnivå motsvarar z = 1,96
5.- 95,5% konfidensnivå motsvarar z = 2.
6.- 99,7% konfidensnivå motsvarar z = 3.
Ett exempel där denna formel kan tillämpas skulle vara i en studie för att bestämma medelvikten för en strands stenar.
Det är uppenbart att det inte är möjligt att studera och väga alla småstenar på stranden, så det är bekvämt.
 figur 2. För att studera egenskaperna hos småstenen på en strand är det nödvändigt att välja ett slumpmässigt prov med ett representativt antal av dem. (Källa: Pixabay)
figur 2. För att studera egenskaperna hos småstenen på en strand är det nödvändigt att välja ett slumpmässigt prov med ett representativt antal av dem. (Källa: Pixabay) Fall 2: Befolkningsstorlek är känd
När numret n av element som utgör en viss population (eller universum) är känd, om du vill välja med enkel slumpmässig provtagning ett statistiskt signifikant provprov, är detta formeln:
n = (z2p q n)/(n e2 + Z2P q)
Var:
-Z är koefficienten förknippad med förtroendetivån.
-P är sannolikheten för framgången för hypotesen.
-Q är sannolikheten för misslyckande i hypotesen, P + Q = 1.
-N är storleken på den totala befolkningen.
-E är det relativa felet i studieresultatet.
Exempel
Metodiken för att extrahera proverna beror mycket på vilken typ av studie som krävs. Därför har slumpmässig provtagning otaliga applikationer:
Kan tjäna dig: tecken på grupperingUndersökningar och frågeformulär
Till exempel i telefonundersökningar väljs människor att konsulteras av en generator för slumpmässiga nummer, tillämpliga på regionen som studeras.
Om du vill tillämpa ett frågeformulär till de anställda i ett stort företag kan valet av respondenter användas via deras anställdsnummer eller identitetskortnummer.
Detta nummer måste också väljas slumpmässigt med hjälp av en slumpmässig generator.
Figur 3. Ett frågeformulär kan tillämpas slumpmässigt att välja deltagare. Källa: Pixabay. QA
I händelse av att studien är på de delar som tillverkas av en maskin måste delar väljas slumpmässigt, men av partier gjorda vid olika tider på dagen, eller på olika dagar eller veckor.
Fördelar
Enkel slumpmässig provtagning:
- Det gör det möjligt att minska kostnaderna för en statistisk studie, eftersom det inte är nödvändigt att studera den totala populationen för att få statistiskt tillförlitliga resultat, med önskade nivåer av förtroende och den felnivå som krävs i studien.
- Undvik förspänning: Eftersom valet av element som ska studeras är helt slumpmässigt, återspeglar studien troget egenskaperna hos befolkningen, även om endast en del av samma studerades.
Nackdelar
- Metoden är inte tillräcklig i fall att du vill veta preferenser i olika grupper eller befolkningsskikt.
I detta fall är det att föredra att tidigare bestämma de grupper eller segment som studien görs. När skikten eller grupperna har definierats, om det är bekvämt för var och en av dem att tillämpa slumpmässig provtagning.
- Det är mycket osannolikt att information om minoritetssektorerna erhålls, av vilka det ibland är nödvändigt att veta deras egenskaper.
Kan tjäna dig: Simpson regel: formel, demonstration, exempel, övningarOm det till exempel är en kampanj för en dyr produkt är det nödvändigt att veta preferenser för de rikaste minoritetssektorerna.
Träning löst
Vi vill studera befolkningens preferens av Cola of Cola, men det finns ingen tidigare studie i den befolkningen, varav dess storlek är okänd.
Å andra sidan måste provet vara representativt med en minsta konfidensnivå på 90% och slutsatserna måste ha ett procentuellt fel på 2%.
-Hur man bestämmer provets storlek?
-Vad skulle vara provstorleken om felmarginalen görs upp till 5%?
Lösning
Eftersom befolkningsstorleken är okänd, för att bestämma provets storlek, används formeln som anges ovan:
n = (z2P q)/(e2)
Vi antar att det finns samma sannolikhet för preferens (P) genom vår förfriskning som för icke -preference (q), sedan p = q = 0,5.
Å andra sidan, som studieresultatet måste ha ett procentuellt fel mindre än 2%, kommer det relativa felet att vara 0,02.
Slutligen producerar ett värde z = 1 645 en 90% konfidensnivå.
Kort sagt, du har följande värden:
Z = 1 645
P = 0,5
Q = 0,5
E = 0,02
Med dessa data beräknas minsta provstorlek:
N = (1 6452 0,5 0,5)/(0,022) = 1691.3
Detta innebär att studien med felmarginalen och med den valda förtroendet måste ha ett urval av respondenter med minst 1692 individer, valda av enkel slumpmässig provtagning.
Om du går från en felmarginal från 2% till 5% är den nya provstorleken:
N = (1 6452 0,5 0,5)/(0,052) = 271
Vilket är ett betydligt lägre antal individer. Sammanfattningsvis är provstorleken mycket känslig för den önskade marginalen i studien.
Referenser
- BERENSON, M. 1985.Statistik för administration och ekonomi, koncept och tillämpningar. Inter -amerikansk redaktion.
- Statistik. Slumpmässigt urval. Taget från: Encyclopediaeconomica.com.
- Statistik. Provtagning. Återhämtat sig från: statistik.Matta.Uson.mx.
- Utdragbar. Slumpmässigt urval. Återhämtad från: utforskande.com.
- Moore, D. 2005. Grundstatistik tillämpad. 2: a. Utgåva.
- Netquest. Slumpmässigt urval. Återhämtat sig från: NetQuest.com.
- Wikipedia. Statistisk provning. Hämtad från: i.Wikipedia.org